
������IStable Diffusion�̎g�����O��K�C�h�F�C���X�g�[�����炨�����߃��f���A��{�I�Ȏg����

�摜����AI�͋ߔN�A�傫�Ȓ��ڂ��W�߂Ă��܂��B���̒��ł��AStable Diffusion�̓e�L�X�g���͂Ɋ�Â��ĉ摜�����邽�߂̃t���[�ŃI�[�v���\�[�X��AI�c�[���ŁA���|�I�Ȓm���x�Ɛl�C���ւ�܂��B
�������AStable Diffusion�����߂Ďg�p���鏉�S�҂ɂƂ��āA�����������̉摜��C���X�g������܂łɂǂ̂悤�Ȏ菇�Ői�߂Ă����悢�̂��A�˘f���Ă��܂����������̂ł͂Ȃ��ł��傤���H
�����ō���́AStable Diffusion�Ƃ͂���Stable Diffusion�����[�J��PC�ɃC���X�g�[���d���A��̓I�Ȏg�����₨�����߃��f���܂ŁA���S�҂ɂ��킩��₷��������Ă����܂��BStable Diffusion�̎g�����Ɋւ��ĕs����Y�݂�����Ă������҂͂��ЎQ�l�ɂ��Ă݂Ă��������B
��������Stable Diffusion�Ƃ�






Stable Diffusion�́AStability AI�ACompVis LMU�ARunway�̎O�҂������Ō��J�������x�ȉ摜�������f���ł��B
���݊g�U���f���ilatent diffusion model�j����ՂƂ��Ă���A�L�[���[�h��e�L�X�g����͂��邾���ŁA�����̃C���[�W�ɋ߂����i���ȉ摜����邱�Ƃ��ł��܂�
�N���E�h�T�[�r�X�o�R�ł̂݃A�N�Z�X�\��DALL-E��Midjourney�i�~�b�h�W���[�j�[�j�ƈقȂ�AStable Diffusion�̓��[�J��PC�ɃC���X�g�[������Ė����Ŏg���܂��B
2022�N�Ɉ�ʌ��J���ꂽ��A�����܂��S���E��AI�摜�̔M���������N�����āA���ԃA�N�e�B�u���[�U�[����1,000���l��˔j���܂����B
1�DStable Diffusion Web UI�Ƃ�
Stable Diffusion�͓���̃A���S���Y���ƃg���[�j���O�f�[�^�Ɋ�Â��摜�������f���ł��B
����AStable Diffusion Web UI�́AStable Diffusion���f�������ȒP�ɗ��p���邽�߂̃u���E�U�C���^�[�t�F�[�X�ł��B�����I�ɑ��삵�₷���̂ŁAStable Diffusion���S�҂ł��摜�����A�C���y�C���e�B���O�A�A�E�g�y�C���e�B���O�A�摜�C���Ȃǂ̋@�\�����S���ė��p���邱�Ƃ��ł��܂��B

Stable Diffusion Web UI�iAUTOMATIC1111�Łj�ɏڂ����Ȃ��������āAStable Diffusion Web UI�Ƃ͉�������A�C���X�g�[���菇�A�K�v��PC�X�y�b�N�A���{�ꉻ�A����ю�ȋ@�\�܂ł��낢��... ������₷������
2�DStable Diffusion�͓��{��Ŏg����́H
Stable Diffusion�iStable Diffusion Web UI�j�̓f�t�H���g�ł͉p��\�L�ƂȂ��Ă��܂����A���{��̊g���@�\���C���X�g�[�����邱�ƂŃ��[�U�[�C���^�[�t�F�[�X��j���[�̕\���Ȃǂ����{��ɕύX����邱�Ƃ��ł��܂��B
Stable Diffusion Web UI����{�ꉻ���邽�߂̐ݒ���@��m�肽���ꍇ�����������Q�l�ɂ��ĉ������B
�Ȃ��A�摜������ۂ̃v�����v�g�����{��œ��͂��邱�Ƃ��\�ł����A�N�I���e�B���������ቺ���Ă��܂��\��������̂ŁA�p��Ńv�����v�g����͂��邱�Ƃ��������߂ł��B
�p��Ɏ��M�̂Ȃ����́AChatGPT�̂悤��AI�`���b�g�{�b�g��Google �|��Ȃǂ̖|��c�[�����g���āA�p��v�����v�g���쐬���邱�Ƃ��ł��܂��B
Stable Diffusion�̃��f���ɂ���
Stable Diffusion�̃��f���Ƃ́A�摜�������s�����߂Ɋw�K����f�[�^�Z�b�g��A���S���Y���̑g�ݍ��킹�̂��Ƃł��B���f���ɂ���Ă��A�����摜�̃N�I���e�B��X�^�C���A���͋C���傫�����E����܂��B�����������摜�ɋ߂����f���𗘗p���邱�ƂŁA�C���[�W�ʂ�̉摜�����邱�Ƃ��ł��܂��B
�Ⴆ�AStable Diffusion�Ƀ��A���E���ʌn�̃��f��������A�v�����v�g�ŃX�^�C���A���͋C���w�肵�Ȃ��Ă��A�t�H�g���A���ȉ摜�����邱�Ƃ��\�ł��B
Civitai��Hugging Face�Ȃǂ̊O���T�C�g����A�g�p������Stable Diffusion�̃��f�����_�E�����[�h�A�C���X�g�[�����邱�Ƃ��ł��܂��B�_�E�����[�h�������f�����umodels\Stable-diffusion�v�ɕ��荞�߂AStable Diffusion Web UI��ŗ��p�ł���悤�ɂȂ�܂��B
Stable Diffusion�̃��f�����_�E�����[�h���ē���������@�ɂ��ẮA�ȉ��̃y�[�W�ŏڂ����菇�ɂ��Ă��Љ�Ă��܂��B

Stable Diffusion�ŗ��p�ł���l�C�̃��f�����Љ�܂��B�܂��A���f���̓������@��g�p���̒��ӓ_�Ȃǂ����킹�Ă��`�����܂��B�ǂ̃��f�����g�����������Ă�����́A���Ђ��̕��͂��`�F�b�N���Ă��������B
Stable Diffusion�̂������߃��f��
Stable Diffusion�̃��f���ɂ͂��낢��Ȏ�ނ����邪�A��\�I�Ȃ��̂��Љ�Ă����܂��B
�@�@DreamShaper�i���\�^�j
- �^�C�v�FCHECKPOINT
- �x�[�X���f���FSD 1.5
- ��ҁFLykon
- �����N�Fhttps://civitai.com/models/4384/dreamshaper
- �T�C�Y�F1.99GB���炢
- ���p���p�F�ꕔ�\
���ʂ����łȂ��A�C���X�g��A�j���A2.5D�Ȃǂ��܂��܂ȃX�^�C���ɑΉ��ł��閜�\���f���ł��B ���𑜓x�ŃN���G�C�e�B�u�ȉ摜���ł��邱�Ƃ������ł��B
�A Anything XL�i�A�j���n�j
- �^�C�v�FCHECKPOINT
- �x�[�X���f���FSDXL 1.0
- ��ҁFYuno799
- �����N�Fhttps://civitai.com/models/9409/or-anything-xl
- �T�C�Y�F6.46GB���炢
- ���p���p�F�ꕔ�\
��l�C�̃A�j���n���f���ł��B�ȒP�ȃv�����v�g���͂����ō��i���ō����ׂȖ����A�j�����̉摜�����邱�Ƃ��ł��܂��B
�B ChilloutMix�i���A���n�j
- �^�C�v�FCHECKPOINT
- �x�[�X���f���FSD 1.5
- ��ҁFTASUKU2023
- �����N�Fhttps:// civitai.com/models/6424
- �T�C�Y�F3.97GB���炢
- ���p���p�F�s��
Civitai�ōł��_�E�����[�h����Ă��郂�f���ł��B���A���ȃA�W�A���l��AI�A�C�h���ɓ��������N�I���e�B�̍����摜�����邱�ƂӂƂ��Ă��܂��B
Stable Diffusion�����[�J��PC�ɃC���X�g�[��������@
Stable Diffusion�����[�J�����Ŏg�p����ɂ́AStable Diffusion�����[�J�����ō\�z���ĂȂ��Ă͂Ȃ�܂���BStable Diffusion�����[�J�����ō\�z����O�ɁA���ݎg�p���Ă���p�\�R�����AStable Diffusion�̓���ɕK�v�ȃX�y�b�N�����Ă��邩�ǂ������m�F����K�v������܂��B
Stable Diffusion�������߂ɕK�v�ȍŒ�X�y�b�N�͈ȉ��̒ʂ�ł��B
- CPU�FIntel Core i5�ȏ�
- �������F8GB�ȏ�
- GPU�FVRM4GB�ȏ�
- �X�g���[�W�F50GB�ȏ�
- OS�FWindows�AmacOS�ALinux
Stable Diffusion���g�p����ۂ�PC�����X�y�b�N�͈ȉ��̒ʂ�ł��B
- CPU�FIntel Core i7��AMD Ryzen 7�ȏ�
- �������F32GB�ȏ�
- GPU�F RTX 3060 �iVRM12GB �j�ȏ�
- �X�g���[�W�F512GB�ȏ�i�ł����1TB�j
- OS�FWindows 10�ȏ�(64bit)
Stable Diffusion ��macOS��Linux�ł�����ł��܂����A���쑬�x�E���萫�̖ʂŗD��Ă���킯�ł͂���܂���B���̂��߁AStable Diffusion�����[�J��PC�ɃC���X�g�[������ۂɋ��߂������Windows��64bit�ł��������߂ł��B
����ł́AStable Diffusion�����[�J��PC�ɃC���X�g�[��������@�ɂ��Đ������܂��B
- Python�̃C���X�g�[���B
Python�̌����T�C�g����ŐV�o�[�W�������_�E�����[�h���ăC���X�g�[�����܂��B
- GIT�̃C���X�g�[���B
GIT�̌����T�C�g����u64-bit Git for Windows Setup�v���_�E�����[�h���ăC���X�g�[�����܂��B
- Web UI�̃_�E�����[�h�E�C���X�g�[��
Stable Diffusion Web UI���i�[����t�H���_��V�삵�āA�J�����t�H���_���ŁA�E�N���b�N�ŕ\������郁�j���[����uOpen Git Bash here�v��I�����܂��B
�^�[�~�i�����J���̂ŁA�ȉ��̃R�}���h����͂���Enter�L�[�Ŏ��s���āA�ustable-diffusion-webui�v�̃t�H���_���쐬����܂��B
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git cd stable-diffusion-webui
�ustable-diffusion-webui�v�̃t�H���_���́uwebui-user.bat�v���_�u���N���b�N���āA�C���X�g�[�����n�܂�܂��B
- �C���X�g�[���̊���
����̋N���ɂ͎��Ԃ�������ꍇ������܂��B��������ƁA�^�[�~�i����Web�T�[�o�[�̃A�h���X�i�ʏ�� http://127.0.0.1:7860�j���\������AStable Diffusion WebUI�������I�ɋN�����܂��B

����ŁAStable Diffusion�����[�J��PC�ɃC���X�g�[�����܂����B�����ẮAStable Diffusio�Ńe�L�X�g�v�����v�g����͂��A�摜����������@���Љ�Ă����܂��B
Stable Diffusion�����[�J�����ō\�z�E����������@���悭������Ȃ��Ƃ������͎��̋L�����Q�l�ɂ��Ă݂ĉ������B

AI�ʼn摜���쐬�ł���Stable Diffusion����������g�������āA�����̃p�\�R���Ƀ_�E�����[�h���܂��B���̋L����Stable Diffusion�����[�J���ɓ���������@�����Љ�܂��BStable Diffusion�̃C���X�g�[�����A���[�J�����̍\�z���A�ʁX�ɂ��������܂��B
Stable Diffusion�̎g����
��������́AStable Diffusion�̎g�����̊�{�I�ȕ�����7�ɕ����āA�Љ�Ă����܂��B���{�ꉻ�ݒ�̎d����Stable Diffusion�̎g�����̃R�c���Љ��̂ŁA�ǂݐi�߂Ȃ�����ۂɉ摜�������s���Ă݂Ă��������B
�܂��́AStable Diffusion Web UI�̃C���^�[�t�F�C�X���猩�Ă����܂��傤�I
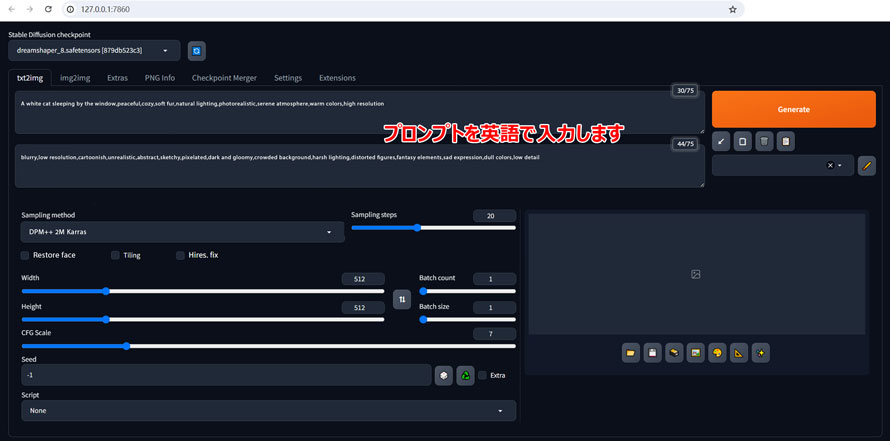
1�DStable Diffusion�̎g�����F��ʂ̌���
�uwebui-user.bat�v���_�u���N���b�N���āAStable Diffusion Web UI���u���E�U�ŊJ�������ƁA���L�̉�ʂɂȂ�܂��B
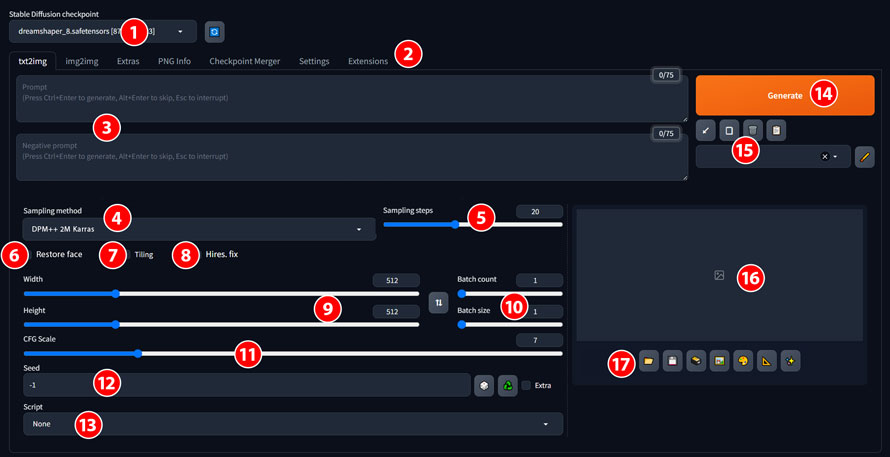
| �ԍ� | ���� |
|---|---|
| �@ | �摜�����Ɏg�����f����I�����܂��B |
| �A | txt2img(�e�L�X�g����摜����)�Aimg2img(�摜����摜����)�AExtras(�T�C�Y�ύX)�APNG info(�v�����v�g�m�F)�Ȃǂ̊Ԃŋ@�\���ւ��܂��B |
| �B | �v�����v�g�ƃl�K�e�B�u�v�����v�g����͂��܂��B |
| �C | �摜������ۂɗp����v�Z�����ł��B�T���v�����O���@�ɂ���āA�m�C�Y�����̕������قȂ�A�ŏI�I�ɐ��������摜�̃N�I���e�B�ƃX�^�C���ɉe����^���܂��B |
| �D | �摜�����܂ł̃T���v�����O�X�e�b�v���ł��B�T���v�����O�X�e�b�v���������قǁA���������摜�̃N�I���e�B���ǂ��Ȃ�܂����A�������Ԃ��x���Ȃ�܂��B |
| �E | ��̏C�����s���܂��B |
| �F | ���������摜���^�C���̂悤�ɕ��ׂ܂��B |
| �G | �摜�����𑜓x�����āA�A�b�v�X�P�[�����O���܂��B |
| �H | �摜�̃T�C�Y���w�肵�܂��B |
| �I | �摜�����̌J��Ԃ��E1��ɐ������閇�����w�肵�܂��B |
| �J | ���������摜�����͂��ꂽ�e�L�X�g�v�����v�g�ɂǂꂾ�������ɏo�͂��邩�𐧌䂷�邽�߂̃p�����[�^�ł��B��ʓI�ɂ́A�u5 �` 10�v���x���������߂ł��B |
| �K | �V�[�h�l���w���܂��B�u-1�v���ƃ����_�������ƂȂ�܂��B����̉摜���������ꍇ�́A���Y�摜�̃V�[�h�l����͂����OK�ł��B |
| �L | ����̃^�X�N��[�N�t���[�����������邽�߂̃R�[�h�̏W���ł��B |
| �M | �摜�������n�܂�܂��B |
| �N | �v�����v�g�A���f���J�[�h�Ɋւ���֗��c�[����[�߂邽�߂̃G���A�ł��B |
| �O | ���������摜���\������܂��B |
| �P | �����摜�̏o�̓t�H���_���J������A�����摜��ۑ�������A�����摜��Zip�ň��k������A�����摜��img2img�Ainpaint�Aextras�ɑ��M���邱�Ƃ��ł��܂��B |
2�DStable Diffusion�̎g�����F���{�ꉻ�ݒ���@
Stable Diffusion�����߂ċN�������ۂɂ́A�f�t�H���g�ł͉p��\���ɂȂ�܂��B�p��Ɋ���Ă��Ȃ����S�҂̕��ɂƂ��ẮAStable Diffusion�̐��E�ɑ��ݓ����͓̂���ł��B�����ɉp��Ŏn�߂Ă��r���Œ��߂Ă��܂��\��������܂��B
�C���X�g�[������Stable Diffusion�iStable Diffusion Web UI�j�����{��\������Ă��Ȃ��ꍇ�͈ȉ��̕��@�Őݒ��ύX���܂��傤�B
- Stable Diffusion���N��������A�uSettings�v�^�u����uAvailable�v��I�����āA�uLocalization�v�Ƀ`�F�b�N���O���܂��B
- �uLoad from�v�{�^�����N���b�N����ƁA�\�����ꂽ�g���@�\�ꗗ�̒�����uja_JP Localization�v��I�����ĉE�[�́uInstall�v���N���b�N���܂��B
- �C���X�g�[��������������A�uExtensions�v�^�u�ɂ���uInstalled�v���J���A�C���X�g�[�������uja_JP Localization localization�v�Ƀ`�F�b�N�����܂��B
- �uSettings�v�^�u���J���A�uUser interface�v�̍��ڂɂ���uLocalization�irequires Reload UI�j�v����uja_JP�v��I�����܂��B
- �Ō�A��ʏ㕔�́uApply Settings�v���uReload UI�v�̏��ɃN���b�N����AStable Diffusion Web UI�����{��ŕ\������܂��B
3�DStable Diffusion�̎g�����F�v�����v�g�E�����̏�����
Stable Diffusion�ʼn摜�������s���ۂɍł��d�v�Ȃ̂̓v�����v�g�i�����j�ł��B�P��ЂƂ����ł�Stable Diffusion�ʼn摜�����͉\�ł����A�v�����v�g�̎w�����e����̓I�Ŗ��m�ł���قǁA�����̃C���[�W�ʂ�̉摜��C���X�g�����܂��B
Stable Diffusion�v�����v�g�̏�������������Ȃ����S�҂́A�ȉ��̊�{�\�����Q�l�ɂ��č쐬���Ă����܂��B
�`�������Ώہ{�`���������̂̏ڍא����{�掿�{�\���X�^�C���{���̂ق��i�w�i��ꏊ�A�V�C�A�\�}�Ȃ��j
�Ⴆ�A�q�L���R���R���Ɠ]����摜���~�����ꍇ�́A���͗��Ɉȉ��̂悤�ȃv�����v�g����͂��܂��B
���L�̂悤�ȉ摜�����܂��B

�l�K�e�B�u�v�����v�g�iNegative Prompt�j�Ƃ́A�摜����AI�ɂ����Đ����������Ȃ��v�f��������w�肷����̂ł��B
�Ⴆ�Alow resolution�i��𑜓x�j�Ablurry�i�ڂ₯���j�Amissing limbs(�葫������Ȃ�)�Amultiple heads�i�����̓��j
Aiarty Image Enhancer
- �g���₷��:���ɃV���v���ł킩��₷�����쐫�B
- AI�œK��:Stable Diffusion�Ȃǂ̐���AI�ɂ���č쐬�����摜�ɍœK�B
- �o�b�`����:�ő�100���̉摜����C�ɍ��掿���ł���B
- AI����:���X���X�ōő�32K�𑜓x�ɃA�b�v�X�P�[������\�B
�l�K�e�B�u�v�����v�g���g�p���邱�ƂŁA�������ꂽ�摜����s�K�ȃX�^�C����s�v�ȗv�f��r���ł��āA�摜�����̐��x���グ��̂ɖ𗧂��܂��B
����AStable Diffusion�ʼn摜������ۂ̃v�����v�g���p��ŋL�q����K�v������A�����̗v�f��w�����J���}�u,�v�ŋ��܂��傤�B���Ɏ������D�悵�����v�f������A�v�����v�g�i�����j�̐擪�Ɉʒu����悢�ł��傤�B
ChatGPT��Google �|��ɉ����āA�����̎��������c�[�������p���邱�ƂŁAStable Diffusion�̉p��v�����v�g�i�����j���쐬���邱�Ƃ��ł��܂��B
Stable Diffusion�v�����v�g�̌��ʓI�ȏ������̃R�c������̎��������c�[���ɂ��āA�ȉ��̋L���ł��ڂ����Љ�Ă��܂��̂ŁA��������Q�l�ɂ��Ă݂Ă��������B

Stable Diffusion���g���A��Ɋ����`�̃C���[�W�╵�͋C�Ȃǂ����Ƃ��ė^���邾���ŁA�N�ł��ȒP�ɃN�I���e�B�̍����摜���쐬�ł��܂��B����̋L���ł́AStable Diffusion�̎����ɂ��Ă̏ڍׂȉ�����s���Ă��܂��B
4�DStable Diffusion�̎g�����Ftxt2img�Ńe�L�X�g����摜������
Stable Diffusion�Ńe�L�X�g����摜������ɂ́Atxt2img�@�\�𗘗p���Ȃ���Ȃ�Ȃ��ł��B
Stable Diffusion��txt2img�@�\�́A���͂����e�L�X�g�v�����v�g�Ɋ�Â��Ďʐ^��C���X�g�Ȃǂ�����@�\�ł��B���̋@�\���g�p���邱�ƂŁA�v�����v�g�̋L�q���H�v����A���i�A�|�[�g���[�g�A�X�P�b�`�A�A�[�g���[�N�A�l�X�ȃW�������̉摜���܂��܂ȃW�������̉摜�������������Ă���܂��B��̓I�Ȏ菇���ȉ��Ɏ����܂��B
- Stable Diffusion Web UI���N��������A�utxt2img�v�^�u���J���܂��B
- �v�����v�g�̃e�L�X�g�{�b�N�X�ɐ����������摜�̓��e���p��œ��͂��܂��B
�����ł́A�uA white cat sleeping by the window,peaceful,cozy,soft fur,natural lighting,photorealistic,serene atmosphere,warm colors,high resolution�v�Ɠ��͂��܂��B
���{��ɒ���Ɓu���ӂŖ��锒�L�A�g���݂̂���A���S�n�̗ǂ��A�_�炩�ȖсA���R���A�ʐ^�̂悤�Ƀ��A���A�Â��ȕ��͋C�A�g�F�n�A���𑜓x�v�Ƃ����Ӗ��ɂȂ�܂��B
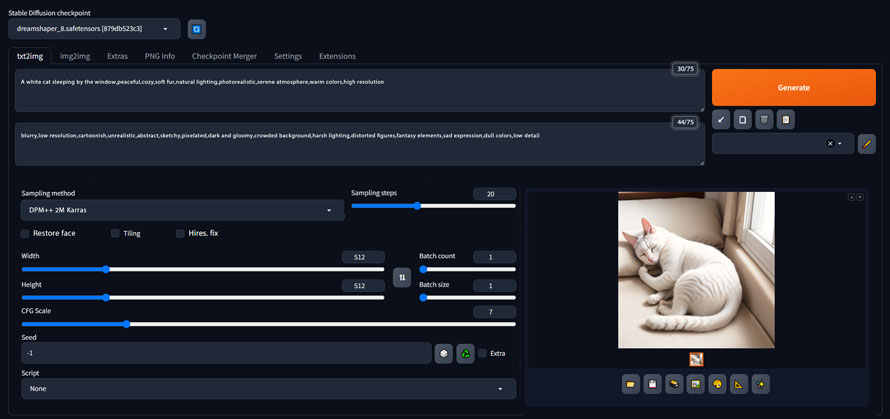
- ��ʉ����̃p�����[�^�ʼn摜�T�C�Y��������Ȃǂ�ݒ肵����A�uGenerate�v�{�^�����N���b�N���܂��B
- ����ƁA��L�̃v�����v�g�̓��e�Ɋ�Â��āAAI���摜�����Ă���܂��B

5�DStable Diffusion�̎g�����Fimg2img�ʼn摜����摜������
�摜����摜�����Ƃ́A�����̉摜�����ɐV���ȉ摜�ݏo���Ƃ����Ӗ��ł��B�\�}��敗�A�X�^�C���Ɏ����摜���ꊇ�ō쐬����̂ɔ��ɖ𗧂��܂��B
Stable Diffusion��img2img�@�\���o�R���ĉ摜����摜��������@���ȉ��Ɏ����܂��B
- �uimg2img�v�^�u���J������A�uGeneration�v→�uimg2img�v�^�u���̃A�b�v���[�h�̈�Ɍ��̉摜���h���b�O&�h���b�v���܂��B
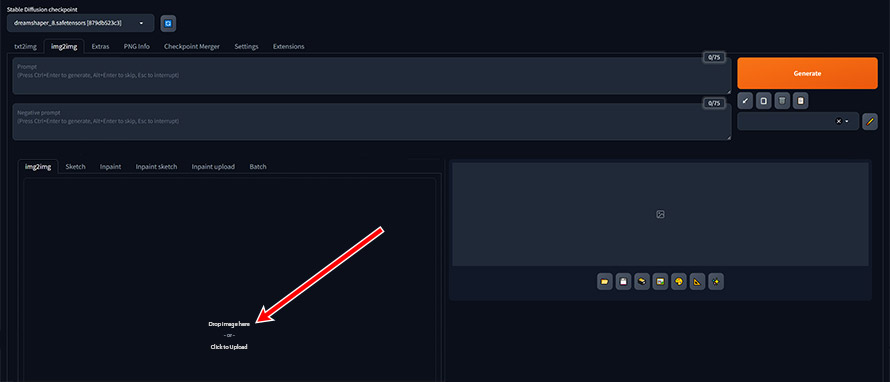
- ��L�̃e�L�X�g�{�b�N�X�ɁA���L�̃v�����v�g����͂��܂��B
�摜�����̐��x�������Ă������߂ɂ́A�摜�i���̌���ɂ��Ẵv�����v�g����͂��Ȃ���Ȃ�܂���B
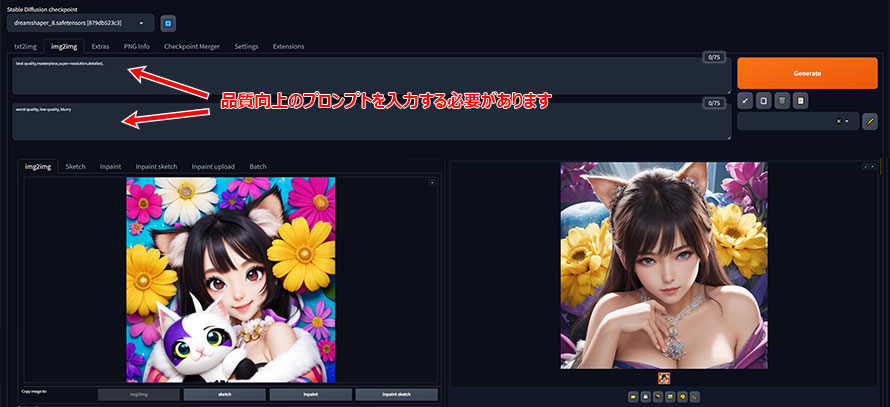
- ��ʉ����̃p�����[�^�ʼn摜�T�C�Y��������A�m�C�Y�������x�Ȃǂ�ݒ肵����A�uGenerate�v�{�^�����N���b�N���܂��B
- ����ƁA���̉摜�Ɏ����摜���V���ɐ�������܂��B


���S�҂̕������ɁAStable Diffusion��img2img�@�\�ɂ��āA��{���삩���̓I�Ȏg�����܂ŏڂ���������Ă����܂��B�܂��AStable Diffusion�ʼn摜����摜�����̋�̗���ڂ��Ă��܂��B
6�DStable Diffusion�̎g�����FExtras�ʼn摜�����𑜓x������
Stable Diffusion��Extras�ɂ́A�摜�����掿��������A�A�b�v�X�P�[�������肷��@�\������܂��B���̋@�\�𗘗p���邱�ƂŁAStable Diffusion �Ő������ꂽ512x512�`512x768�𑜓x�̉摜���S�{�܂Ŋg�傷��Ɠ����ɁA����ɍ��掿�ɂ��Ă���܂��B
- �uExtras�v�^�u���J������A���𑜓x���������摜���A�b�v���[�h�̈�Ƀh���b�O&�h���b�v���܂��B �܂��́Atxt2img�Eimg2img�́u���̑��ɓ]���v����摜�𑗐M���邱�Ƃ��ł��܂��B
- �摜�����ɂ���uScale by�v�^�u�́uResize�v�̃X���C�h�o�[���X���C�h������Ɗg��̔{����ύX���܂��B�uScale to�v�^�u�Ŋ�]�̉𑜓x�ڂɎw�肷�邱�Ƃ��ł��܂��B
- Upscaler 1�E2�ʼn摜���X�P�[���A�b�v����ۂɗp����v�Z������I�����܂��B
- �uGenerate�v�{�^�����N���b�N����Ɖ摜���A�b�v�X�P�[������܂��B
�ł�Stable Diffusion�ʼn摜�����掿������ꍇ�́APC�̃��C�����������啝�ɐ�L����AGPU��CPU�̎g�p�ʂ�������̂ŁA�������x���x���Ȃ�����A���삪�s���肱�Ƃ�����܂��B���Ɉ�ʓI�ȉƒ�p�̃p�\�R���ł́A�ق�90%�̊m���Ő���ɓ��삵�܂���B
���̏ꍇ�́AAI�摜�ɓ����������掿���\�t�g�́uAiarty Image Enhancer�v�����邱�ƂŁAStable Diffusion�̐����摜�����掿��������A�ő�32K�𑜓x�܂ŃA�b�v�X�P�[�������肷�邱�Ƃ��ł��܂��B
7�DStable Diffusion�̎g�����F���������摜�͂ǂ��ɕۑ������̂��H
Stable Diffusion Web UI�ō쐬���ꂽ�摜��C���X�g�́A �f�t�H���g�œ���̃f�B���N�g���i�t�H���_�[�j�Ɏ����I�ɕۑ�����܂��B�ʏ�́A�uoutputs�v�̃t�H���_�[����т��̃T�u�t�H���_�[�Ɋi�[����邱�Ƃ������ł��B
��̓I�ȕۑ��ꏊ�͉��L�̒ʂ�ƕ\������Ă��܂��B
- �e�L�X�g���琶�����ꂽ�摜�̕ۑ��ꏊ�Fstable-diffusion-webui\outputs\txt2img-images
- �摜���琶�����ꂽ�摜�̕ۑ��ꏊ�Fstable-diffusion-webui\outputs\img2img-images
- Extras�ʼn��H�����摜�̕ۑ��ꏊ�Fstable-diffusion-webui\outputs\extras-images
Stable Diffusion�̏��p���p�E���쌠�ɂ���
Stable Diffusion�Ő��������摜��C���X�g�́A��{�I�ɏ��p���p���\�ł��B
�Ƃ����̂��AStable Diffusion�Ő��������摜��C���X�g�̒��쌠�́A�쐬�������[�U�[�ɋA�����Ă��邽�߁A���[�U�[���g��Stable Diffusion�ɂ���Đ������ꂽ���̂����p���p�܂߂Ď��R�ɗ��p���邱�Ƃ��ł��܂��B
�������A�ꍇ�ɂ���Ă͒��쌠�N�Q�ƂȂ�\��������܂��̂Œ��ӂ��K�v�ł��B
�Ⴆ�A���p���p���F�߂��Ȃ����f���ɂ���Đ�������Ă���摜�̏ꍇ�A���p���p�͋֎~����Ă��܂��B
�܂��Aimg2img�̋@�\���g���ĉ摜����V���ȉ摜������ꍇ�A�Q�l�̉摜�ɂ���ẮA���쌠�N�Q�ɂȂ��Ă��܂����˂܂���B
���̂��߁AStable Diffusion�ʼn摜�������s���O�ɁA�e���C�Z���X�◘�p�K���K���m�F���邱�Ƃ���ł��B

���̋L�����������l�F����
�摜���ʐ^���H�𒆐S�ɁA�ŐV��AI�\�����[�V������\�t�g�E�F�A�ȂǂɊւ���𗧂����^�C�����[�ɂ��͂����܂��B